
EYaTToCoding
엑셀(Excel) 파워쿼리(PowerQuery)를 활용한 네이버 부동산 데이터 수집 본문
엑셀로 간단히 데이터 크롤링 하기
엑셀로 크롤링하는 방법은 크게 VBA와 파워 쿼리 두 가지로 나뉜다. VBA는 코드 작성이 필요해 크롤링 전반에 대한 프로그래밍 지식이 요구되지만, 파워 쿼리를 이용하면 별도의 코딩 없이 직관적인 인터페이스만으로 데이터를 손쉽게 수집할 수 있다. 특히, 파워 쿼리는 반복 작업을 자동화하는 기능이 탁월해 데이터를 주기적으로 갱신해야 하는 경우에도 유리하다.
엑셀은 시트당 최대 1,048,576개의 행으로 제한된다. 따라서 수집하려는 데이터가 100만 건 미만이라면 엑셀을 통해 수집하는 것이 별도의 전문 프로그램을 사용하는 것보다 간단하고 효율적이다. 또한, 데이터 수집과 분석을 동일한 플랫폼에서 진행할 수 있어 작업 시간이 대폭 줄어든다.
이번 글에서는 네이버 부동산을 예제로 삼아 파워 쿼리를 이용해 데이터를 수집하는 과정을 보여주도록 하겠다. 파워 쿼리의 강력한 기능을 활용해 코딩 없이도 어떻게 데이터를 가져오고, 정리하며, 필요한 형태로 변환하는지 함께 살펴보자.
엑셀(Excel) 파워쿼리(PowerQuery)
엑셀 파워쿼리란?엑셀 파워 쿼리(Power Query)는 데이터를 가져오고 변환하는 데 특화된 엑셀의 도구이다. 이를 통해 다양한 데이터 원본(예: Excel 파일, CSV, 데이터베이스, 웹 등)에서 데이터를 불러
eyatto-coding.tistory.com
네이버 부동산 페이지 확인
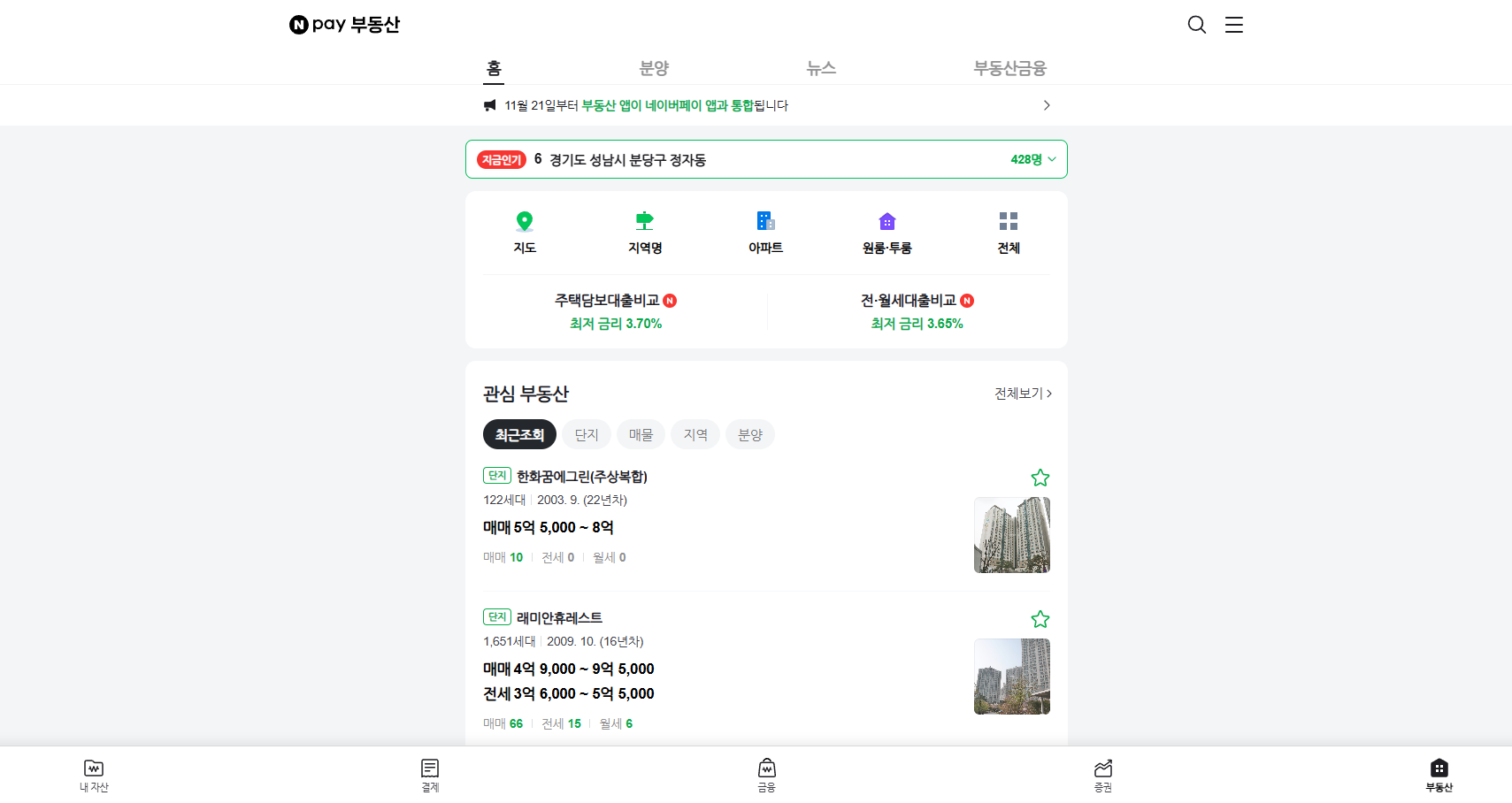
네이버 부동산은 pc버전과 mobile 버전이 있다. 그중 더 깔끔하게 정보를 확인할 수 있는 곳이 mobile이다. 따라서 mobile버전을 기준으로 설명한다. pc를 통해 네이버 부동산 페이지로 접속하면 아래 사진과 같은 페이지가 나타난다. 그리고 검색, 지도, 지역명, 분양정보, 뉴스 등을 함께 확인할 수 있다.
네이버페이 부동산
네이버페이 부동산
fin.land.naver.com
선택지들 중 지역을 선택해 고양시 덕양구 화정동을 들어가 보았다. 들어가 보면 파란색 원으로 매물 수가 나타난다. 그리고 지도를 확대, 축소 하게 되면 파란색 원의 개수가 늘었다 줄었다 하는것을 확인할 수 있다. 이것은 결국 지도 크기에 따라 지역별 매물을 군집화하여 갯수만 보여준다는것을 의미한다. 이것을 확인할 수 있는 예시는 개발자 도구(F12)를 열어보면 확실히 알 수 있다.
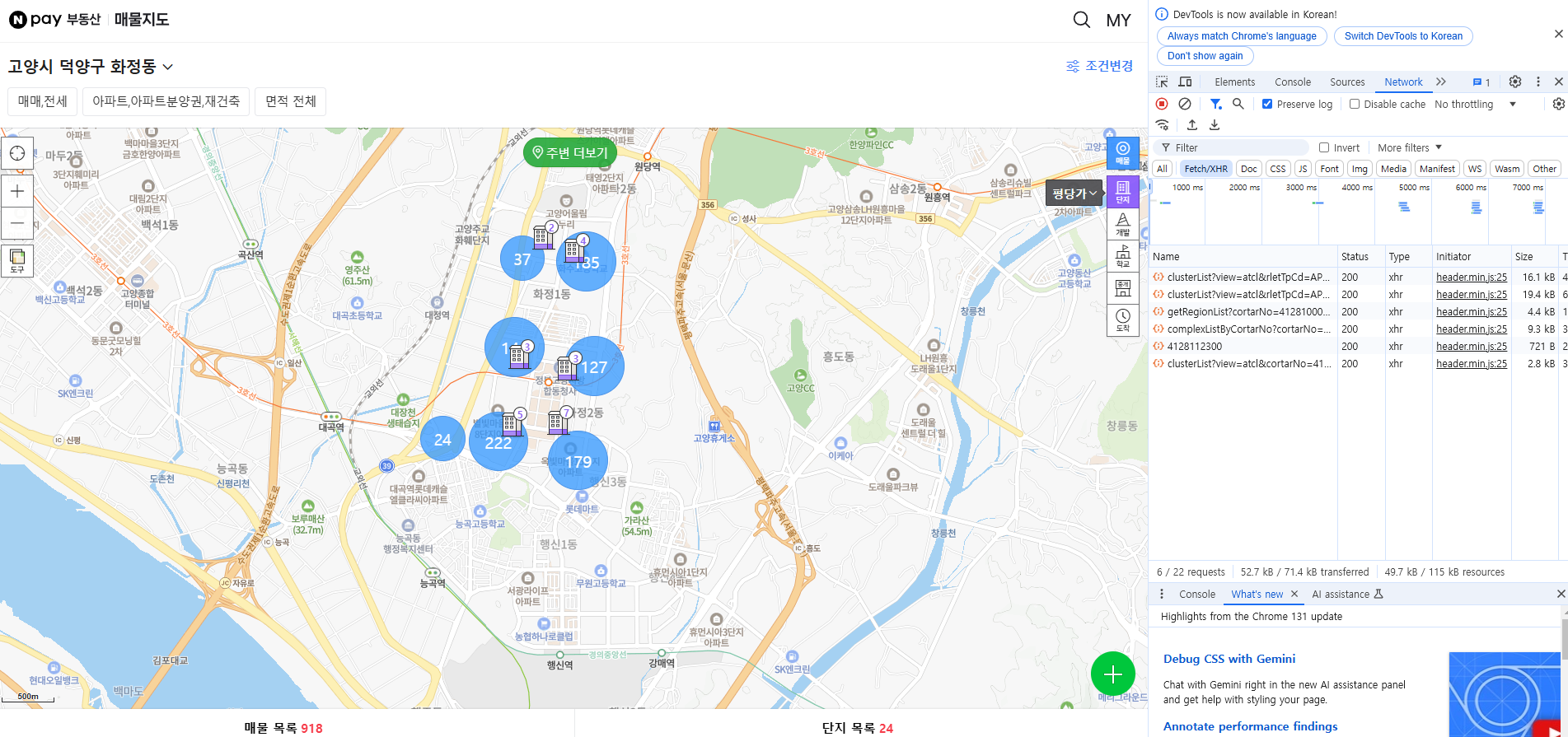
개발자 도구를 열고 데이터를 불러오는 곳을 확인한다. network > Fetch/XHR을 들어가 새로고침을 눌러보면 Name칸에
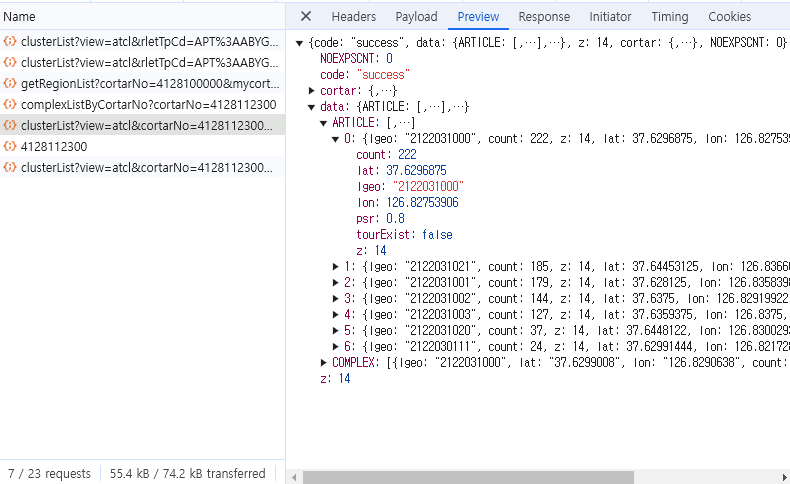
clusterList?view=.... 라는 부분이 있고, 그것을 클릭해서 Preview를 보면 원의 개수만큼 json형식으로 데이터가 들어와 있는것을 확인할 수 있다. 그리고 각 부분은 count, lat, lon, psr, tourExist, z 라는 값을 가지고 있다.
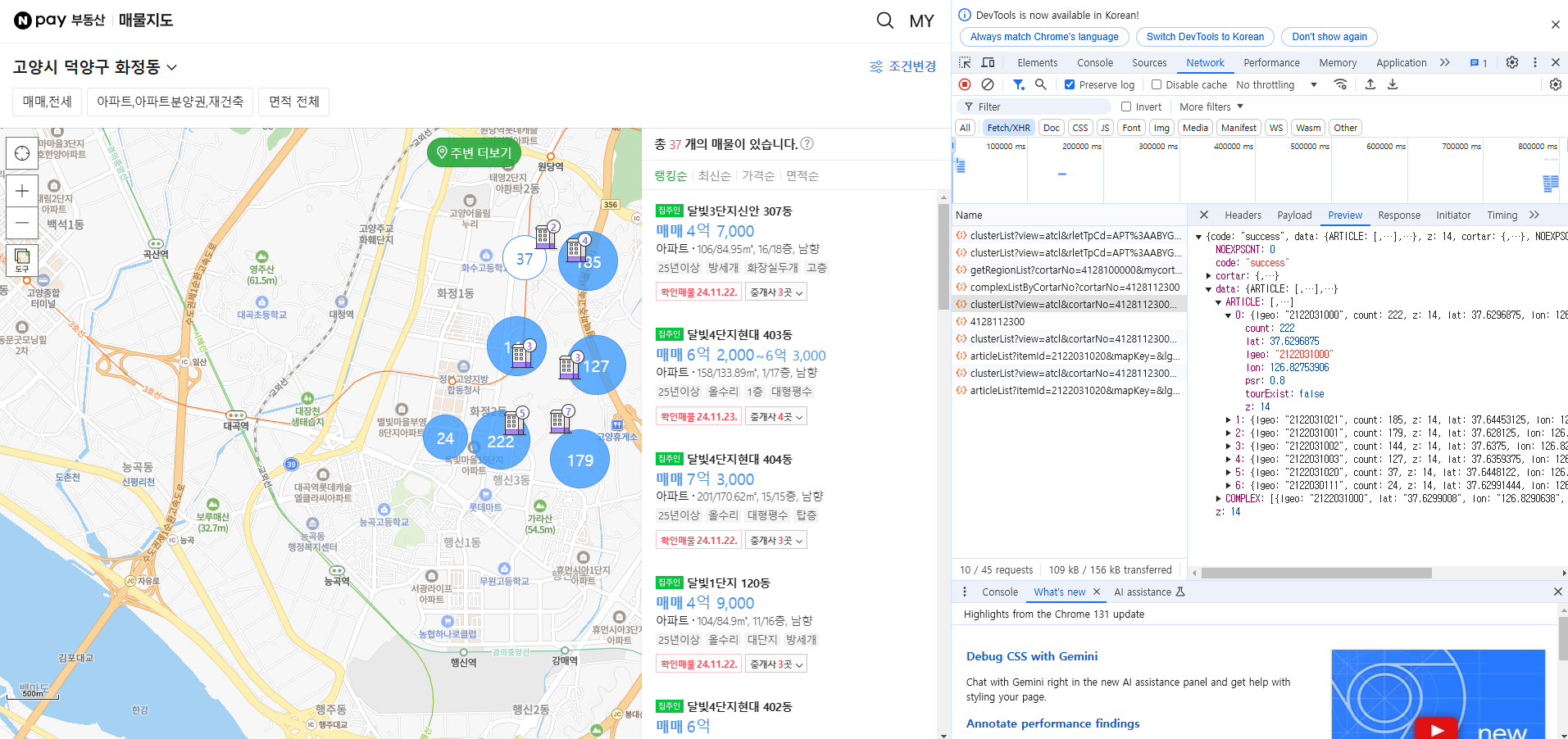
매물 데이터 확인
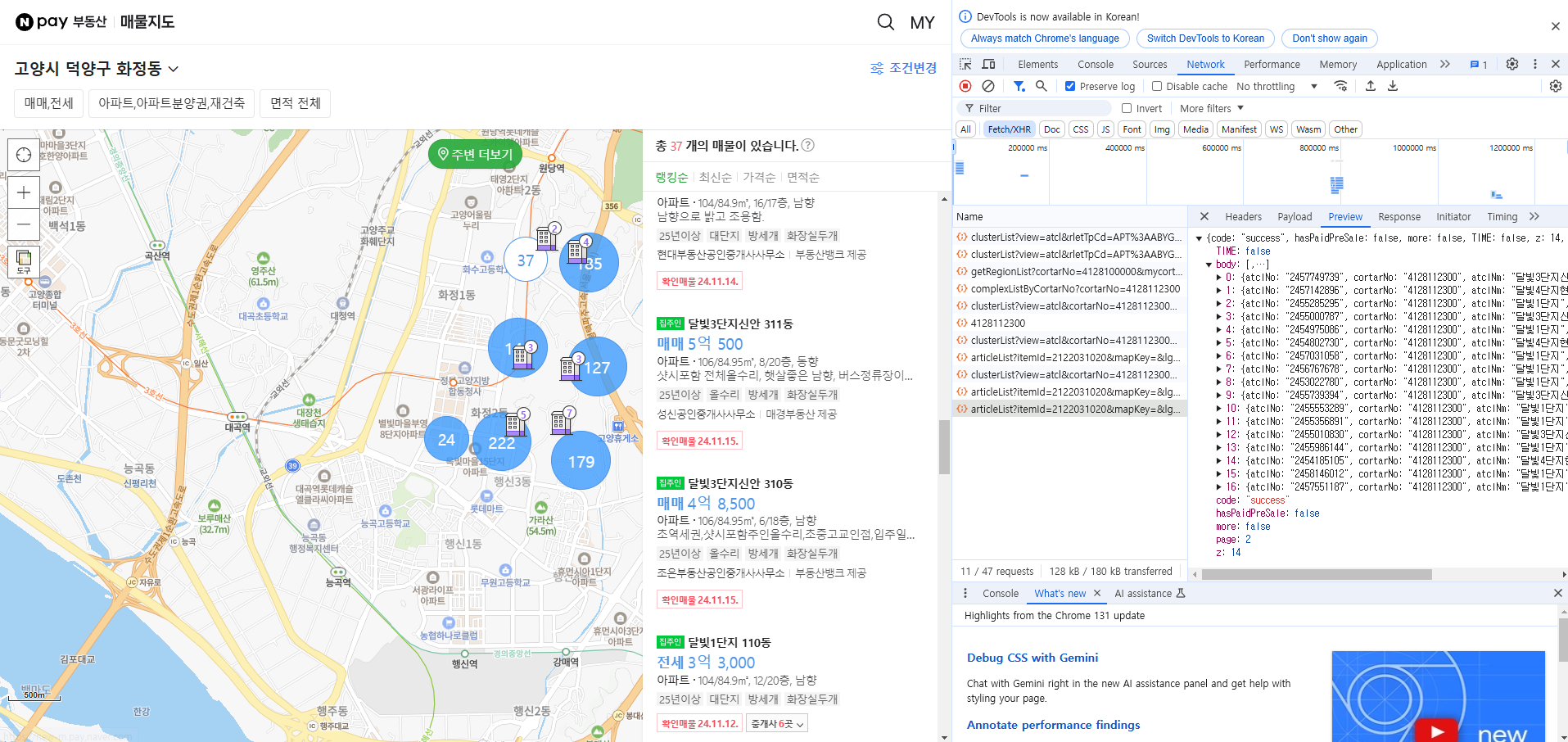
이제 매물을 확인해본다. 파워쿼리에서 어떻게 데이터를 가져오는지 확인하는것이 목적이기 때문에 매물이 비교적 적은 37, 145, 24 동그라미의 매물만 확인하고 가져오도록 하겠다. 먼저 37이라고 되어있는 동그라미를 클릭하면 저렇게 오른쪽에 매물이 나타난다. 그리고 개발자도구 Name칸에 articleList?itemId.... 라는 파일이 하나 생성된다.
새로 생성된 파일을 클릭하고 Preview를 확인하면 아래와 같은 데이터가 들어오는것을 확인할 수 있다. 20개의 데이터가 들어온다. 이유는 네이버부동산의 경우 동적으로 움직이는 페이지 이기 때문에 처음 데이터는 20개씩 들어온다. 0을 눌러보면 오른쪽 그림과 같이 데이터가 펼쳐진다. 내용은 매물 리스트의 제일 위에 있는 정보임을 확인할 수 있다.
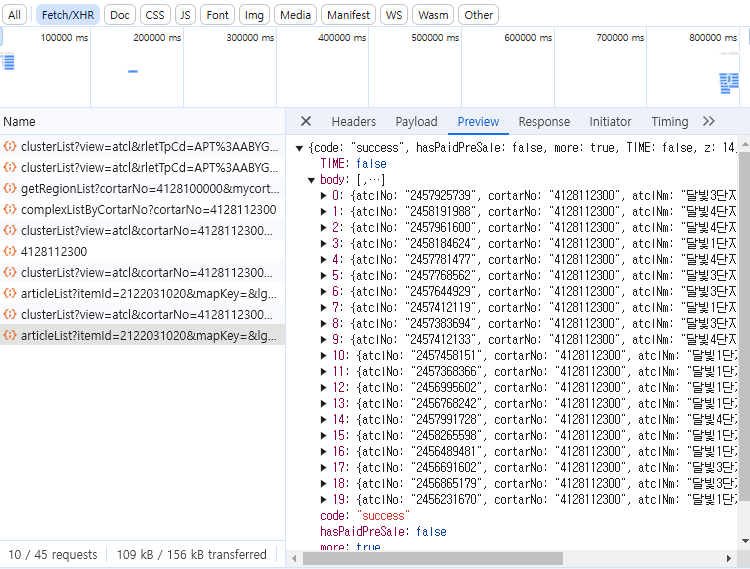
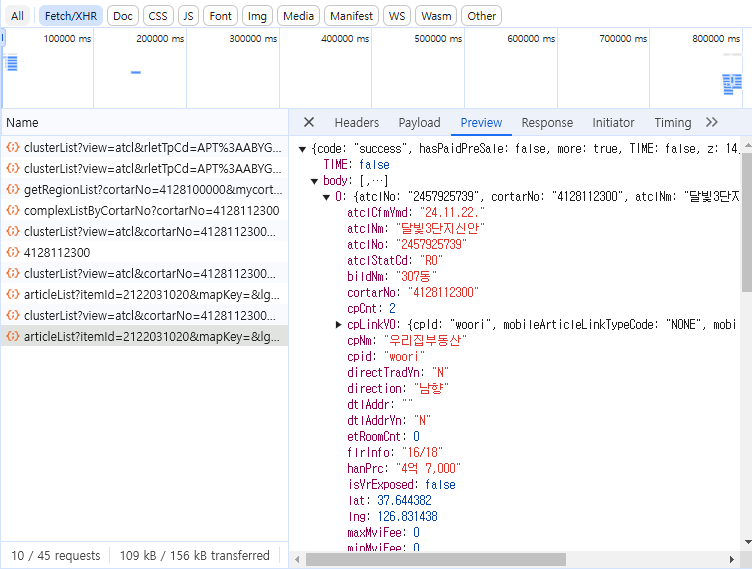
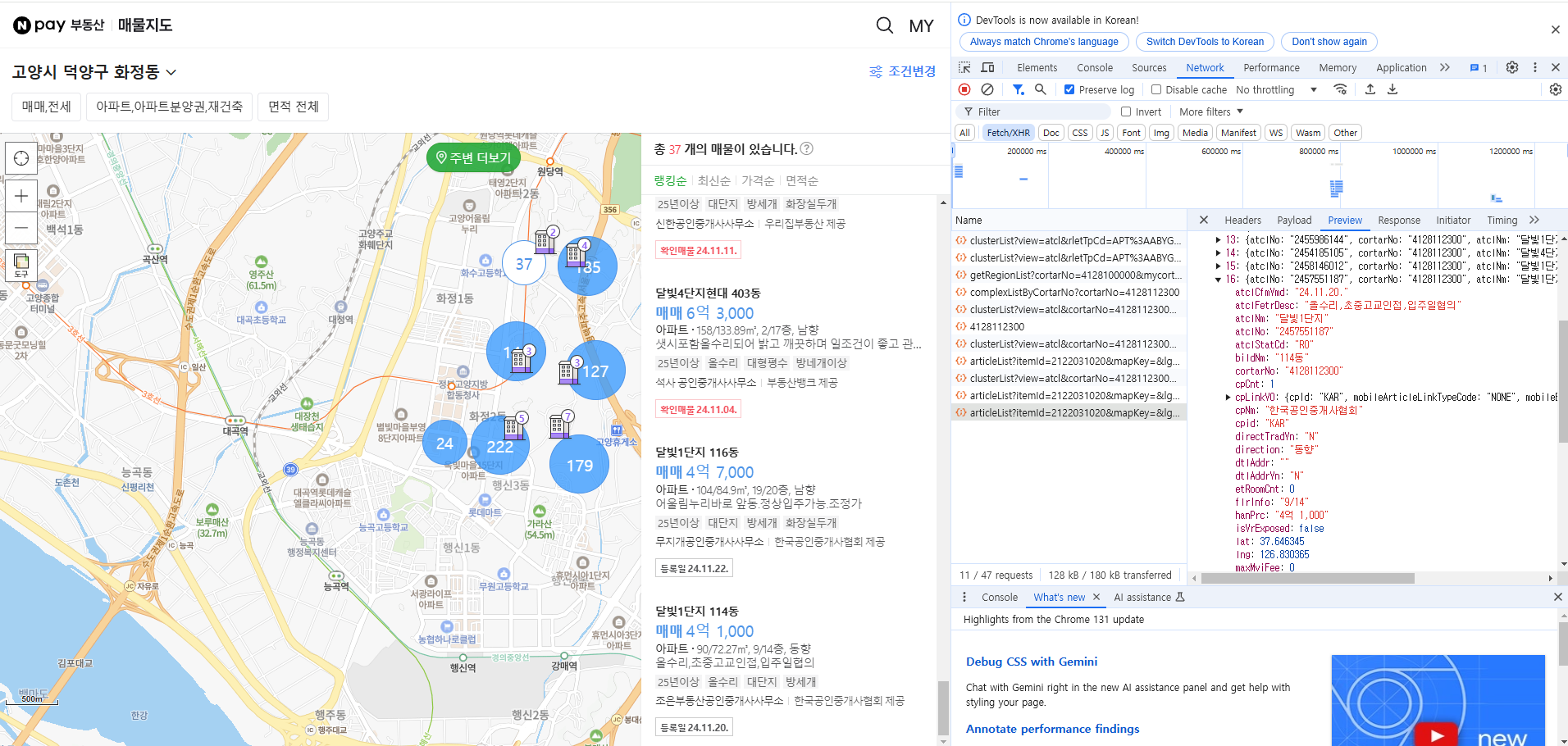
이제 화면에서 천천히 매물리스트가 있는 스크롤을 내린다. articleList?itemId... 라는 파일이 하나가 더 생성되는것을 확인할 수 있다. 이 파일을 눌러 Preview를 확인해보면 17개의 데이터가 들어오고 제일 마지막 리스트와 화면에 나타나는 매물이 일치하는것을 확인할 수 있다. 이로써 37동그라미에 해당되는 매물 37개의 데이터를 모두 찾았다.
파워쿼리를 이용한 크롤링
위의 과정을 통해 동그라미에 해당하는 매물 데이터를 찾았다. 이제 이 데이터들을 파워쿼리를 이용해 엑셀로 저장할 것이다. 먼저 파워쿼리를 통해 데이터를 가져오려고 하면 데이터가 들어있는 URL이 필요하다. 이 URL은 개발자 도구의 Headers에서 확인 할 수 있다. 2차로 세부 매물 데이터(17개)를 확인한 개발자도구 창에서 Headers를 클릭한다. 그러면 사진과 같은 창이 보일 것이다. 거기서 General > RequestURL을 복사하고 크롬 새창에서 열어본다. 그러면 위에서 봤던 json형식의 데이터가 나타난다.
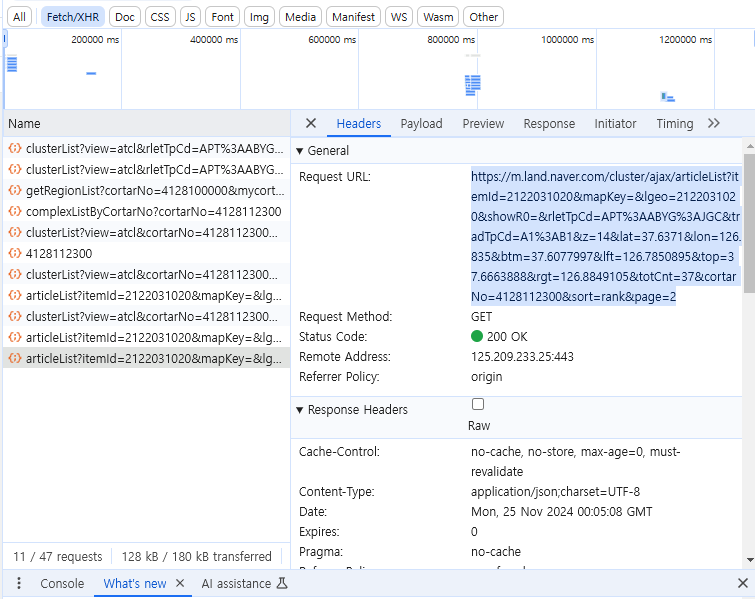

새창에 url을 입력했을 때 나타나는 json 데이터를 확인했다. url을 확인해 보니 제일 뒤에 page 가 있는것을 확인할 수 있다. 앞서 네이버에서는 데이터를 조회할때 20개만 조회한다고 언급했다. 그런데 37개의 데이터를 가져오려고 하다보니 두번에 나눠 데이터를 가져온 것이다. 이것이 url에서 page라는 파라미터로 표시되게 된 것이다. 따라서, 처음본 20개의 데이터는 page=1로 변경하게 되면 나오게 된다.
// url 뜯어보기
https://m.land.naver.com/cluster/ajax/articleList?itemId=2122031020&
mapKey=&
lgeo=2122031020&
showR0=&
rletTpCd=APT%3AABYG%3AJGC&
tradTpCd=A1%3AB1&z=14&
lat=37.6371&lon=126.835&
btm=37.6077997&
lft=126.7850895&
top=37.6663888&
rgt=126.8849105&
totCnt=37&
cortarNo=4128112300&
sort=rank&
page=2 // page=1, 2로 번갈아가면서 봐볼것
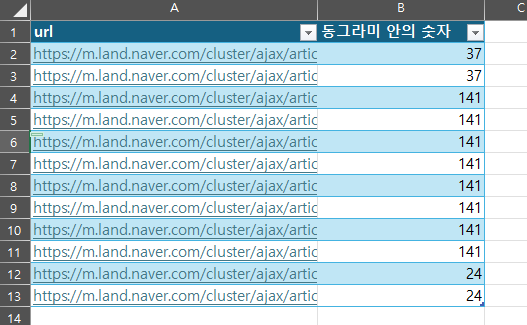
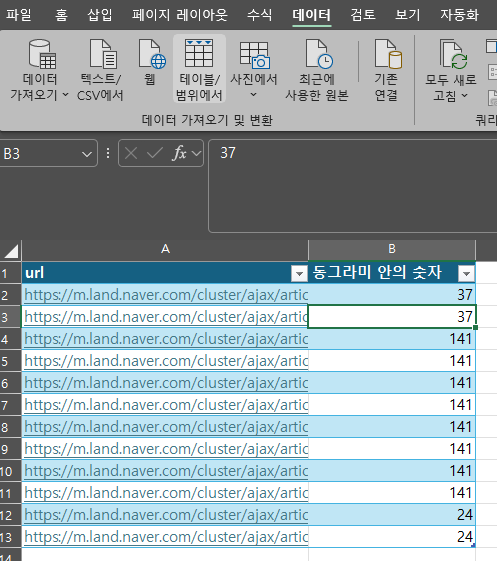
그럼 이제 엑셀을 켜서 저 url을 붙여넣고 표로 만들어준다(ctrl + t). 지금까지 진행했던 동일한 방법으로 141개의 매물이 있는 동그라미와 24개의 매물이 있는 동그라미의 url도 넣어준다. 그럼 총 12개(2개 + 8개 + 2개)의 url이 되겠죠? 그리고 나서 만든 테이블에 커서를 두고 데이터 > 테이블/범위에서를 클릭한다.
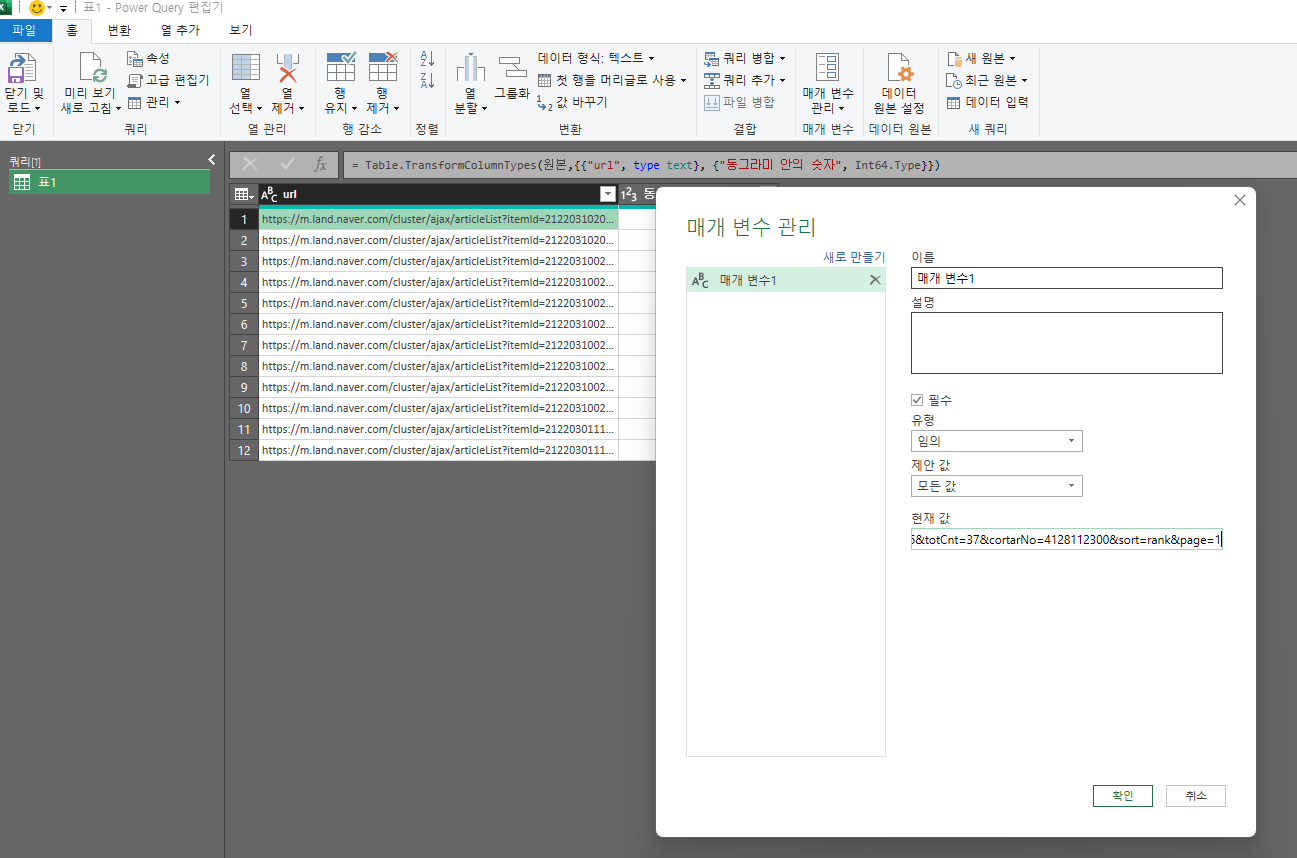
그럼 아래 사진과 같이 파워쿼리 편집기가 열리게 된다. 첫번째 셀을 클릭해 복사한다(ctrl + c). 그리고 리본메뉴에서 매개변수관리 > 새 매개변수 > 현재값에 복사한 내용을 붙여넣기 한다. 이후 새원본 > 기타원본 > 웹을 클릭한다 그리고 url을 매개변수로 바꿔주면 새로 생성했던 매개변수 이름이 나타나게 된다. 그리고 확인을 눌러준다.
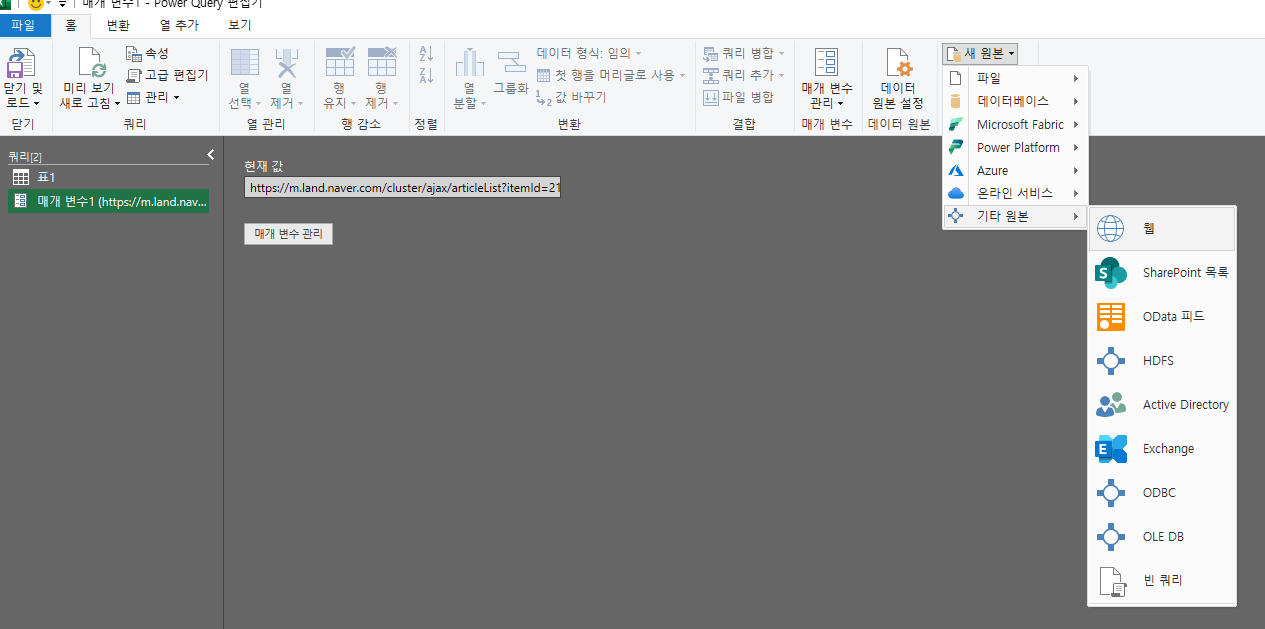
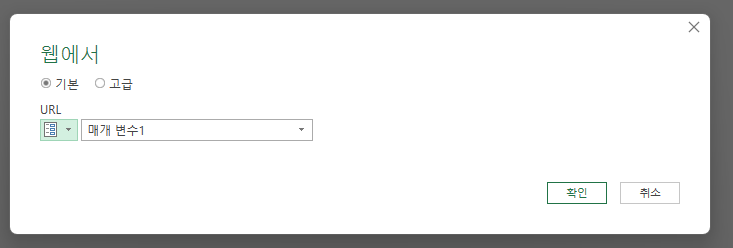
그러면 아래와 같은 사진이 나타나게 된다. 이때 body의 list를 클릭해주면 오른쪽 사진처럼 변하게 되고 위의 테이블로 버튼을 눌러준 후 확인을 누른다.

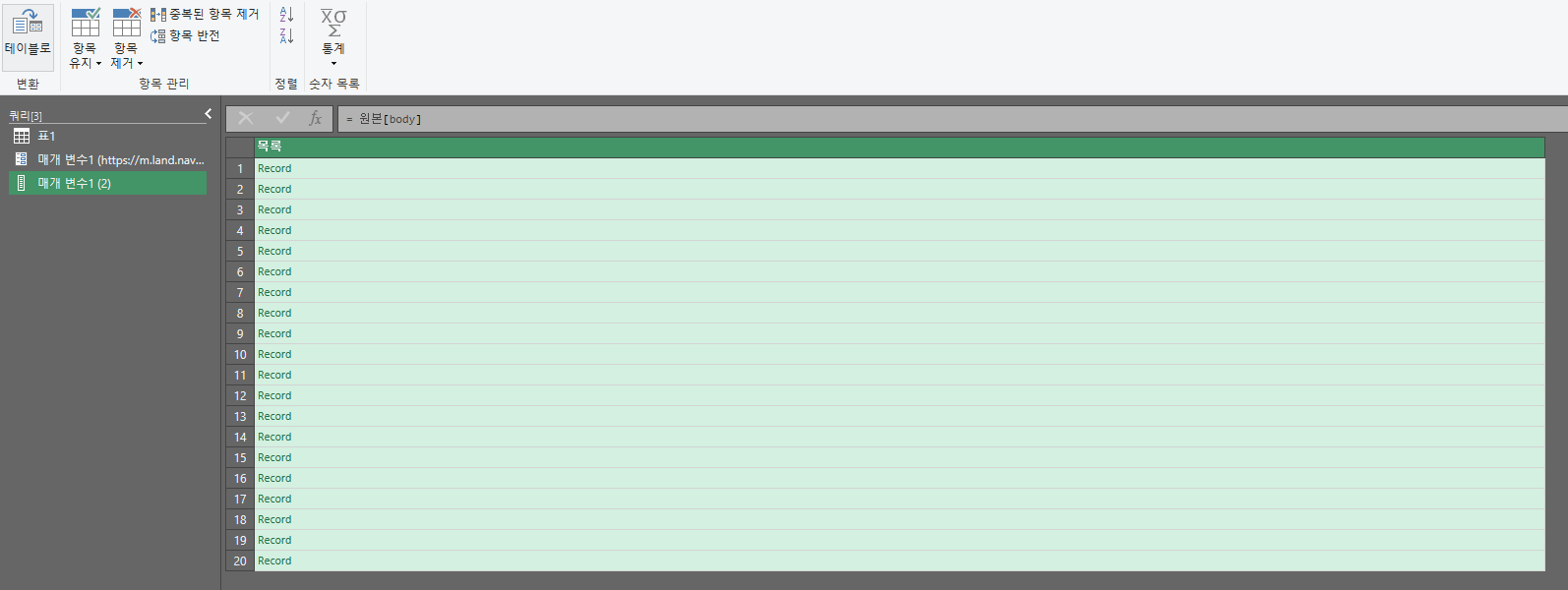
그러면 아래와 같은 사진이 나타나게 되는데 표 옆의 양갈래 화살표를 누르면 json데이터에서 본 값들이 들어가 있는것을 확인할 수 있다. 여기서 원래 열 이름을 접두사로사용 부분이 체크되어 있을텐데 이것을 해제 한 후 확인을 눌러주면 첫번째 url에 대한 데이터를 보두 가져오는것을 확인할 수 있다.
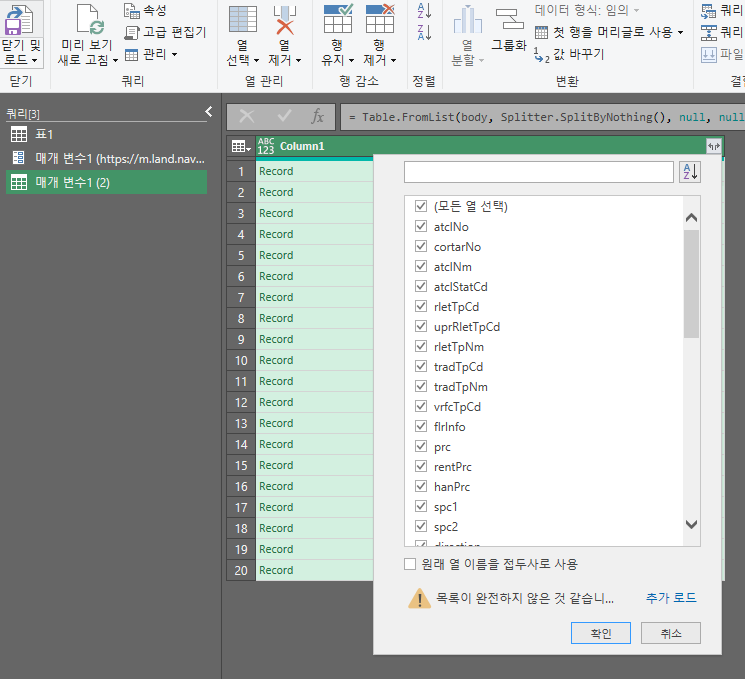
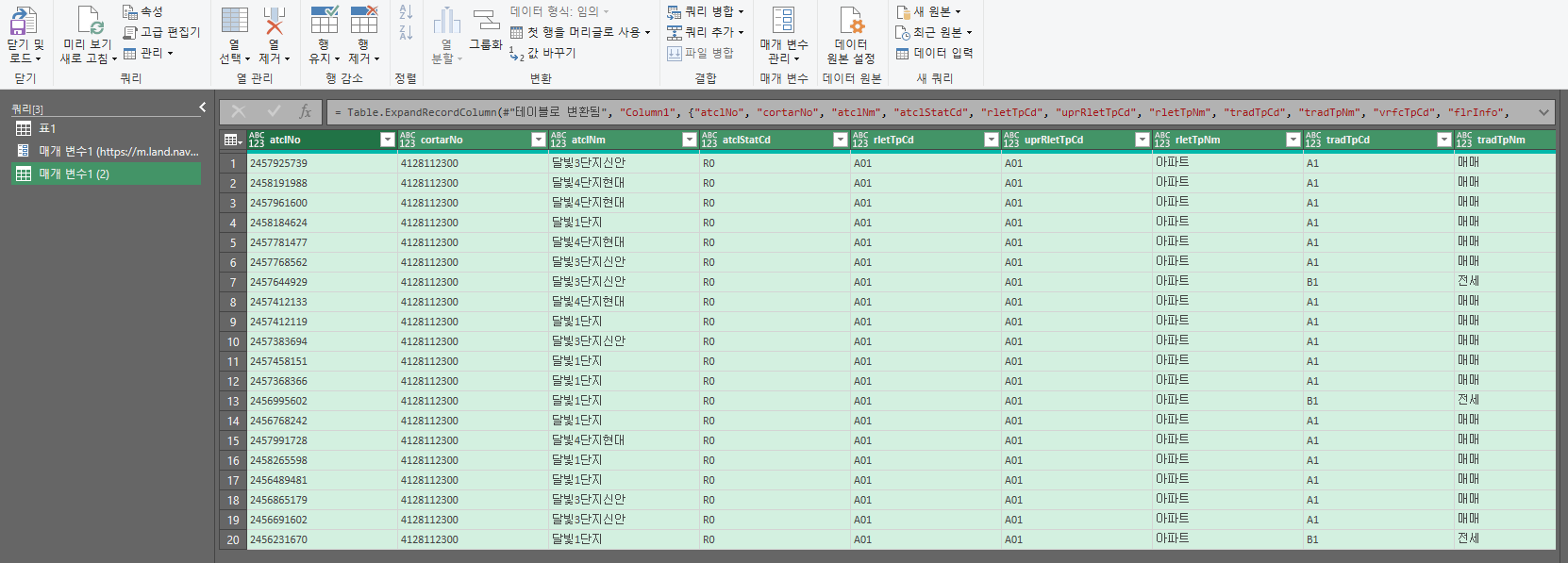
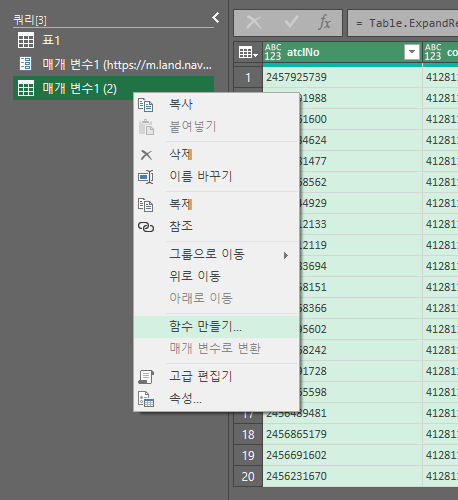
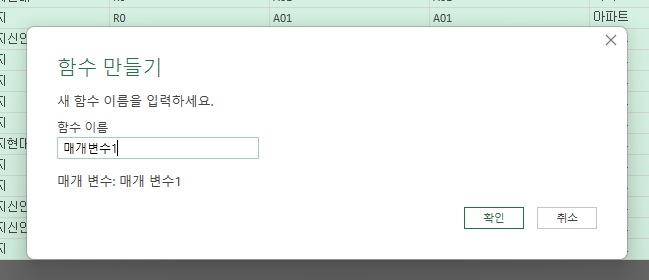
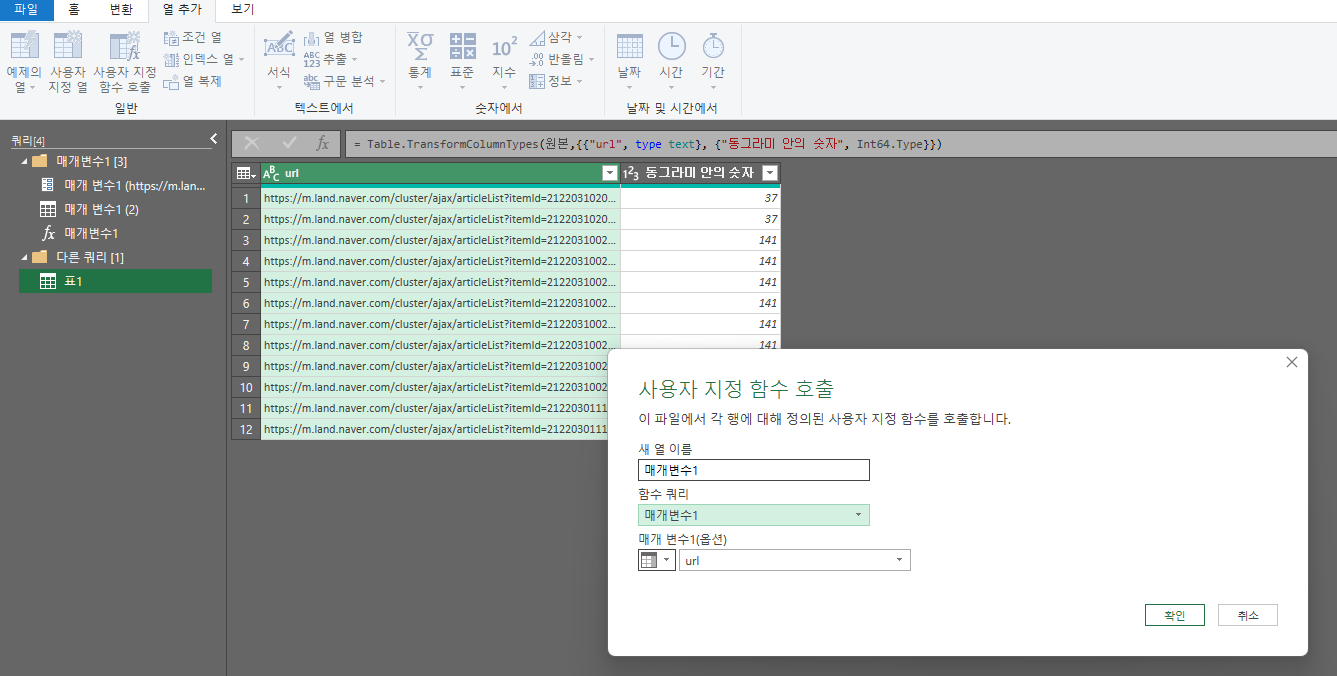
이 과정을 거치면 url한개를 크롤링 할 수 있는 것이다. 만약 url이 500개라면? 이 작업을 500번 해야겠지...? 그래서 이제 이 부분을 함수화 하여 다른 url에도 적용한다. 이를 위해 최종 표로 나온 저 부분에서 마우스 우클릭을 한 후 함수로 만들기를 클릭해 준다(애초에 함수로 만들기를 하기 위해 위에서 매개변수를 만든것임.). 함수이름은 아무거나 정해준다. 나는 매개변수1로 했다. 그러면 3번째 사진처럼 나타나게 될 것이다.
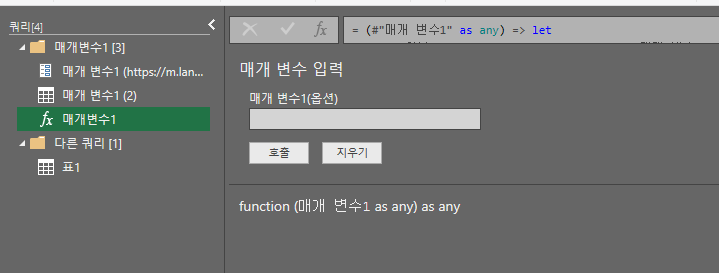
그럼 이제 다른쿼리라는 폴더 하위에 표1을 클릭하면 처음 파워쿼리에 들어왔을때 표가 있을 것이다. 여기서 상단 메뉴의 열추가를 클릭해 주고 사용자 지정 함수 호출을 클릭한 후 함수쿼리를 위에서 만들어둔 함수 이름(매개변수1)을 클릭한다. 그리고 확인을 클릭 > 계속 클릭 > 체크박스 클릭 > 저장 클릭
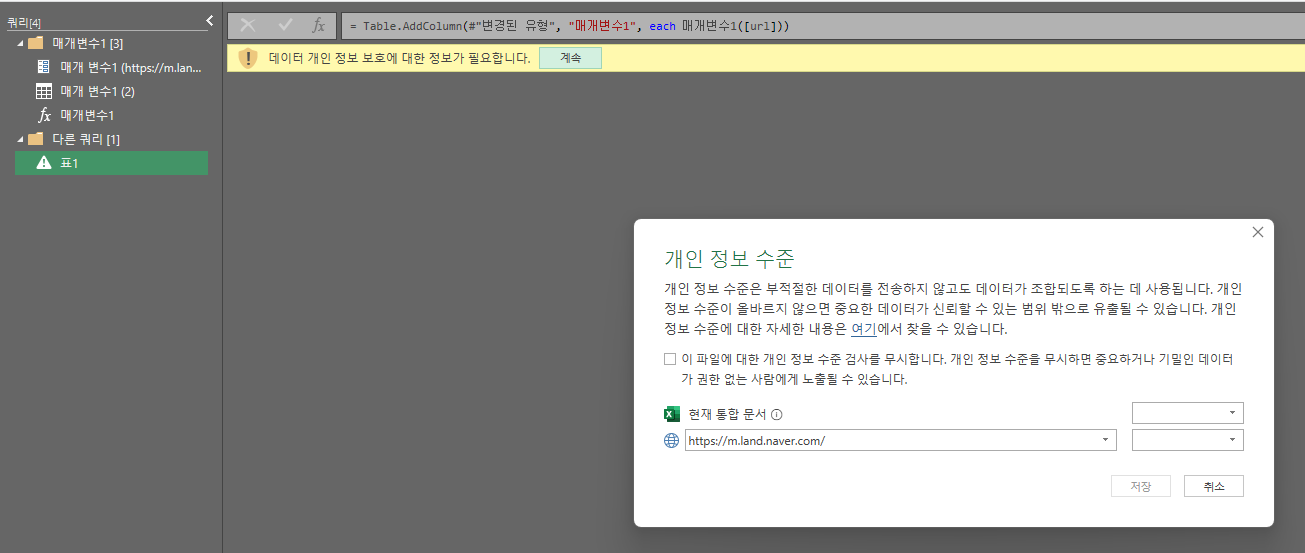
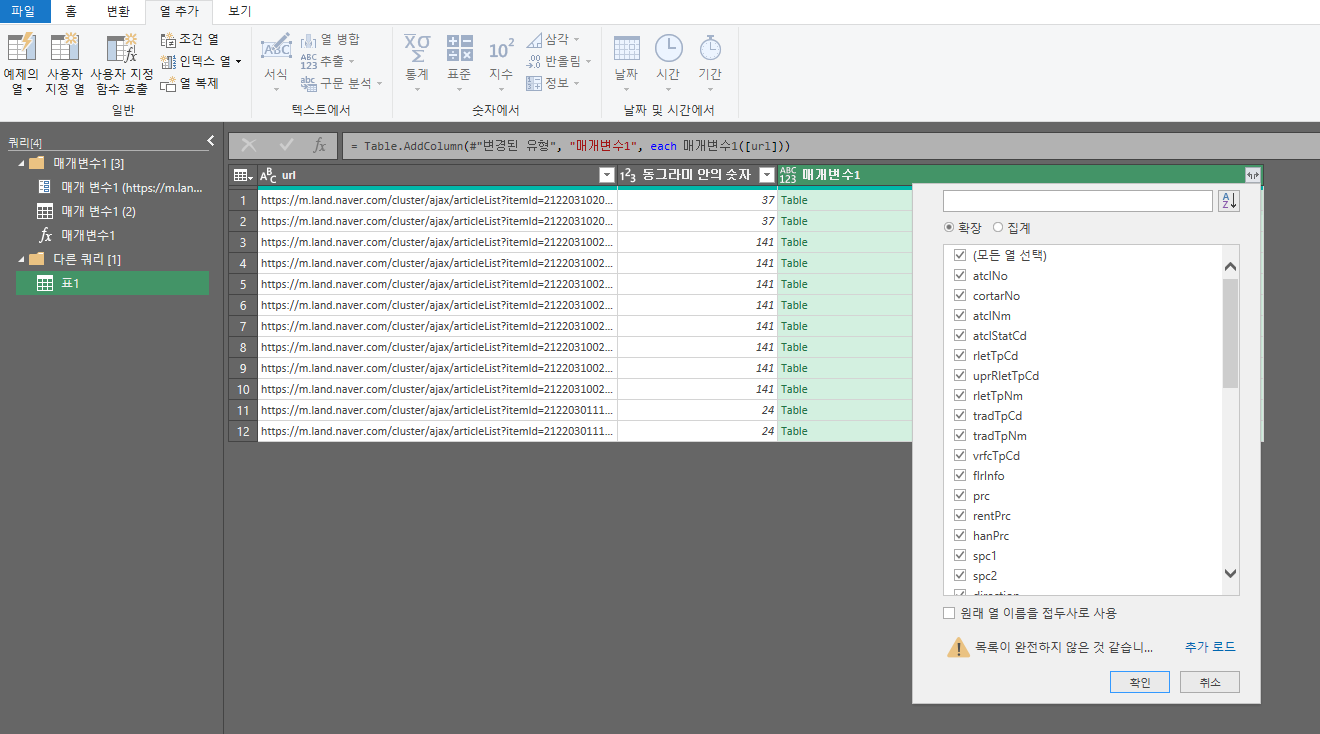
여기까지 하면 매개변수1이라는 컬럼이 추가되면서 양갈래 화살표가 나타난다. 아까와 동일하게 원래 열 이름을 접두사로사용을 체크 해제하고 확인을 누르면 모든 url에 함수가 적용되어 모든 데이터를 크롤링 할 수 있다.
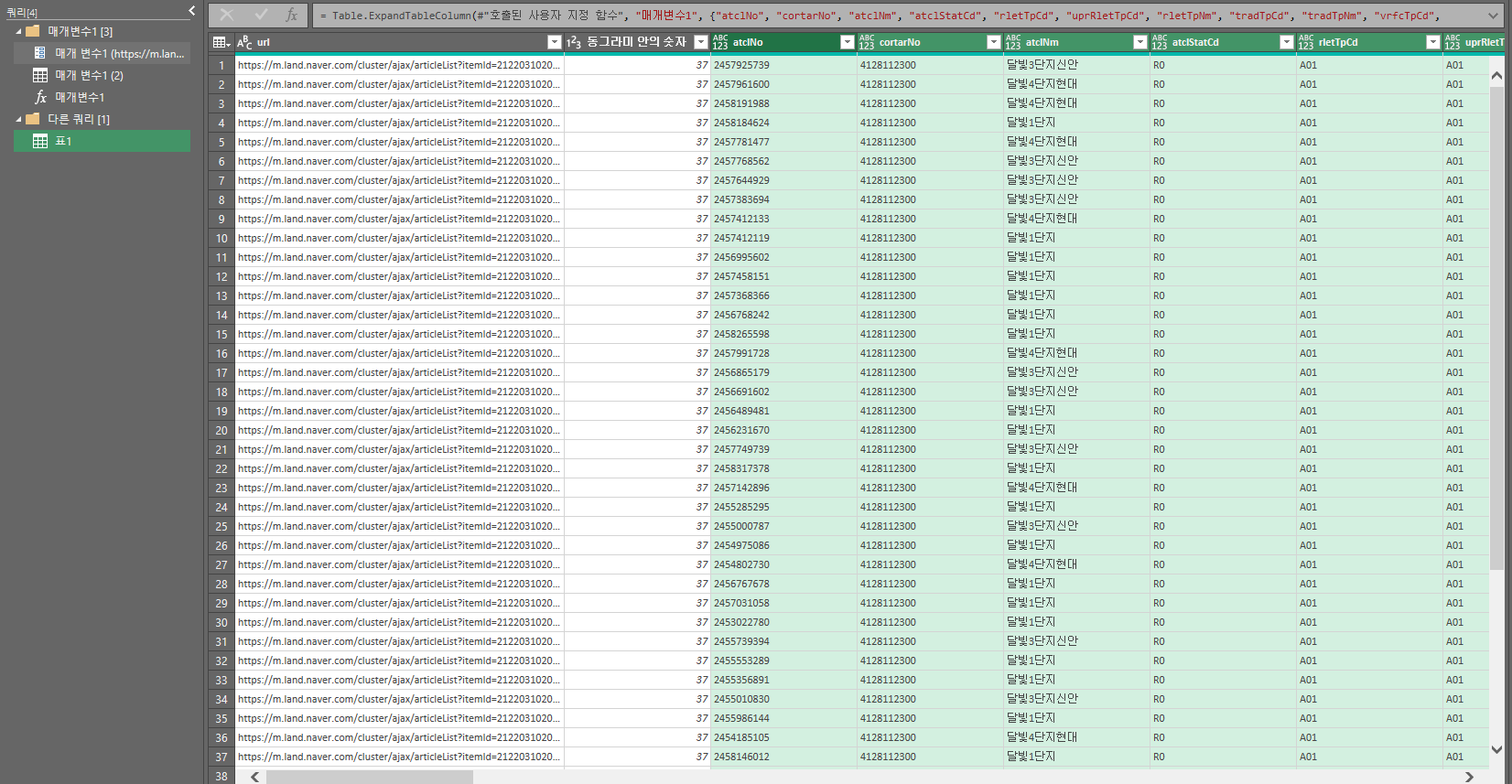
자 이제 마지막으로 상단 메뉴 홈에서 닫기 및 로드를 누르면 206개의 데이터가 들어와 있는것을 볼 수 있다!
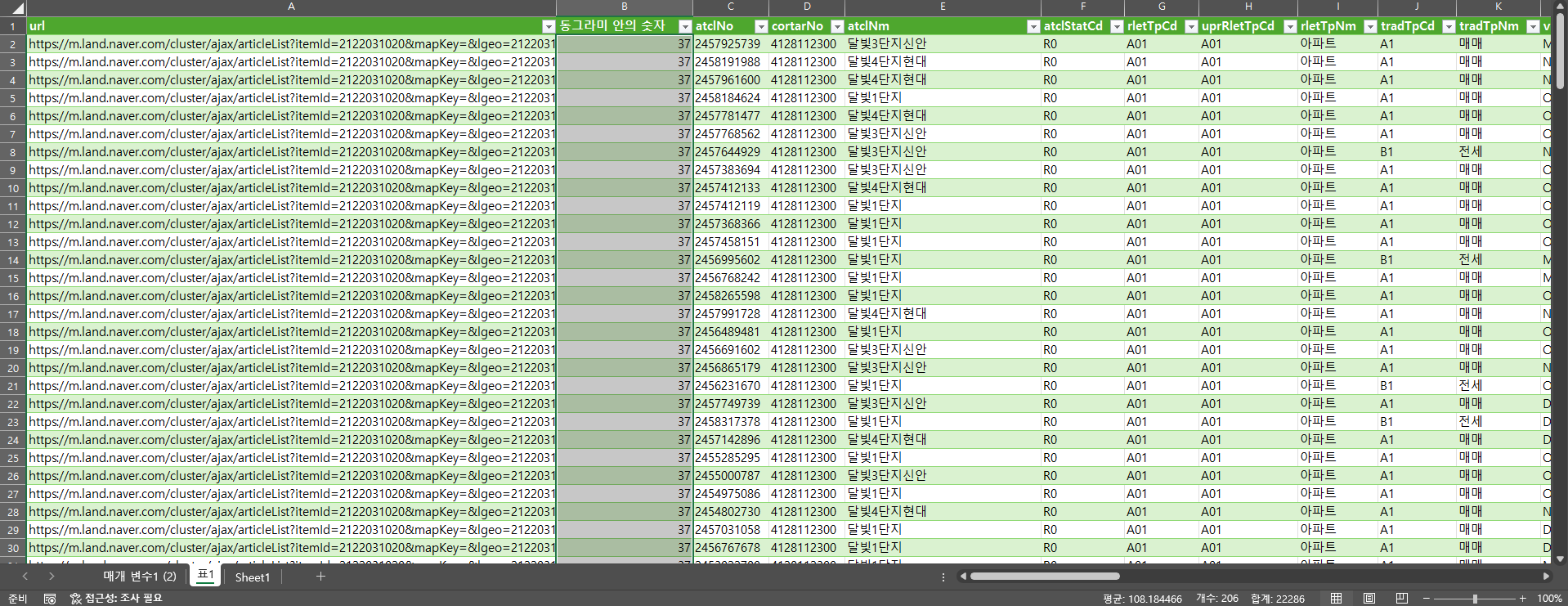
파워쿼리를 이용해 데이터를 크롤링 하는 방법을 알아보았다. 몇개 안되는 url로 진행했지만 사실 노가다로 한다면 이 방법으로도 충분히 많은 데이터를 수집할 수 있다. 본인이 코딩을 할 줄 안다면 엑셀의 VBA나 python의 beautifulSoup을 활용해 더 많은 데이터를 수집하고 처리할 수 있을 것이다.
기회가 된다면 모두 포스팅 하도록 하겠다.